Andreas Olofsson ·
Analyzing the RISC-V Instruction Set Architecture
I was very excited to read the recent EE Times article “RISC-V: An Open Standard for SoC” by Krste Asanović and David A. Patterson announcing their open source processor architecture. As we near the end of CMOS scaling, the bulk of future performance and efficiency improvements will need to come from architecture improvements. The availability of a high quality open processor architecture will help tremendously in this area.
Looking through the RISC-V ISA specifications [1], I couldn’t resist comparing it to the Epiphany ISA [2], and wanted to share the results in case others might find the comparison useful.
The book “Computer Architecture: A Quantitative Approach”, by John Hennessy and David Patterson was my constant companion during 2008 when I created the Epiphany architecture, so it should come as no surprise that the two architectures are more similar than different.:-) Having defended my own ISA choices for 6 years now, I can confidently state that there is no right answer to most of the “zero-sum” decisions that need to be made during the definition process. My favorite Fallacy/Pitfall advice from the Hennessy/Patterson book:
- Fallacy: You can design a flawless architecture
- Fallacy: An architecture with flaws cannot be successful
Figure 1 and 2 shows a summary of the two architectures, highlighting some of the similarities and differences and as well as some of the architectural design choices. For comparison purposes, I chose to compare the “IMAF” version of the RISC-V since this mostly closely resembles the Epiphany architecture in terms of a standard feature set. Both architectures were designed for extensibility and modularity, so it’s easy to add and remove key functionality for special purpose applications. However, as we have seen in the past, the importance of binary compatibility should never be under-estimated. For this reason, even if an ISA is modular and configurable, once it reaches mass adoption it is likely to stabilize around one configuration.
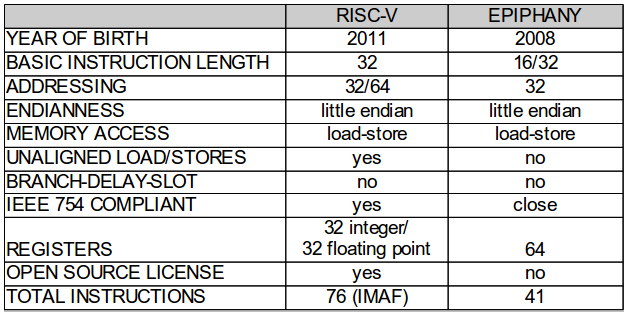
Figure 1: Comparing the RISC-V and Epiphany
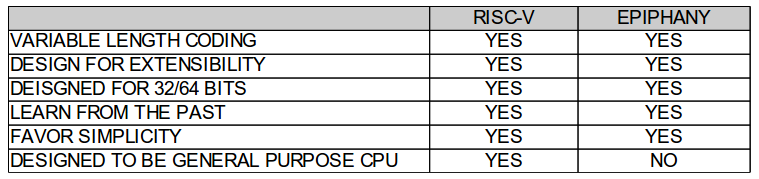
Figure 2: Design Philosophy
The two architectures were designed for completely different purposes; the Epiphany was designed to function as a math coprocessor while the RISC-V was designed to run the full software stack. As a general purpose processor, the RISC-V must be good at everything so it must include more instructions to be complete.
Both architectures are silicon proven. A 40nm 64-bit RISC-V (RV64IMA (no floating point)) implementation with 32KB of cache occupies 0.39mm^2.[3] In contrast, a 28nm 32-bit Epiphany implementation with 32KB of local SRAM and a Network-On-Chip occupies 0.13mm^2.[4]
The sections below include a more detailed analysis of the ISAs, with my own Epiphany biased comments added.
Branching
Both architectures implement complete support for branching and function support, albeit with a different approach. The Epiphany performs conditional moves and branches based on condition codes (like on ARM, PowerPC) while the RISC-V performs conditional branching based on comparison between two registers. Refer to the specifications[1,2] for more details.

Figure 3: Branch/Control Instructions
Load/Store
The RISC-V has support for loading signed byte and half word loads, which is clearly an important feature for working with signed byte and half word data types. Some may argue that the RISC-V could use more addressing modes to boost efficiency in compute intensive applications. True to its DSP heritage, the Epiphany architecture places more emphasis on addressing modes and even includes a postmodify addressing mode for accessing sequential in memory buffers more efficiently. The Epiphany also includes support for double word loads/stores which is needed to keep the floating point working at maximum capacity in most applications.
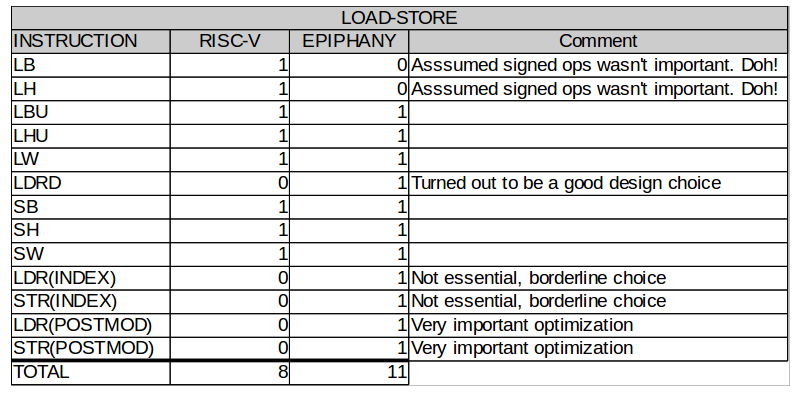
Figure 4: Load/Store Instructions
Integer
The RISC-V has significantly more integer instructions than Epiphany to support a broader set of applications. It should be noted that the Epiphany performs surprisingly well on non-DSP benchmarks despite its minuscule instruction set.[5] The ingenuity of compiler developers and the optimization prowess of state of the art compilers like GCC and LLVM should never be under estimated. The Epiphany does not include many operations on immediates because it was assumed to be: a.) non-essential, and b.) possible to implement these functions effectively with the compiler.
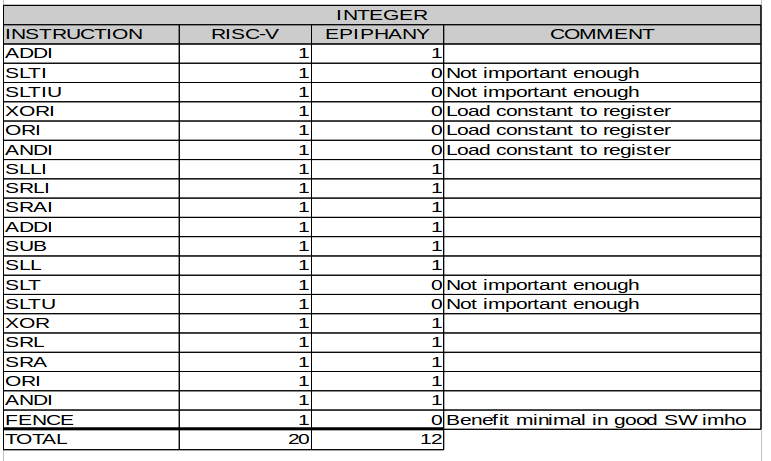
Figure 5: Integer Instructions
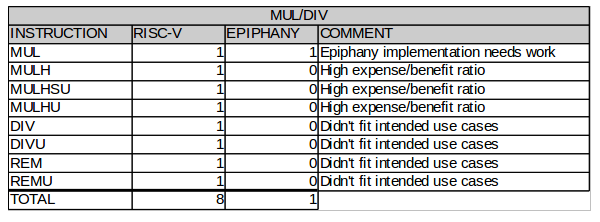
Figure 6: Multiply/Divide Instructions
Floating Point
The RISC-V represents a well tested standard floating point instruction set with a very broad application range. The Epiphany again shows traces of its DSP heritage. Since most signal processing algorithms boil down to a simply multiply accumulate operation, the original DSPs were design to be super optimized programmable multiply accumulate units run in a tight programmable for loop.
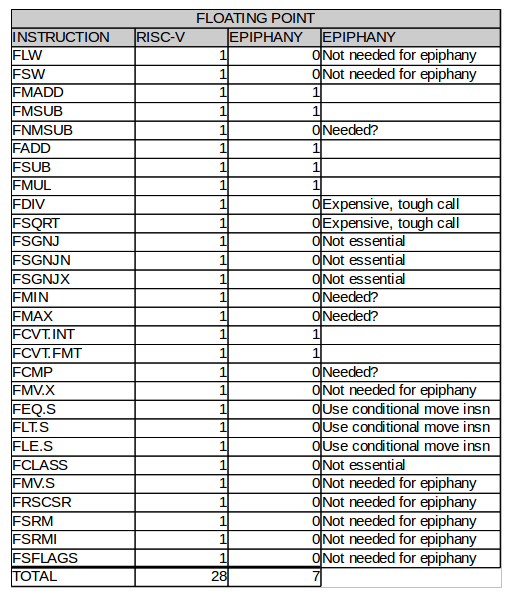
Figure 7: Floating Point Instructions
Conclusion:
The RISC-V and Epiphany are both representative of the RISC approach to computer architecture that Patterson and others invented long ago. The RISC-V architecture is not revolutionary, but it is an excellent general purpose architecture with solid design decisions. The true breakthrough here is really the open source licensing model and the maturity of the design as compared to most other open source hardware projects. I am personally very enthusiastic about the kinds of low cost systems that will be built around this RISC-V architecture going forward. A royalty free 64-bit RISC-V core would have a raw silicon cost of a couple of cents in current CMOS process nodes. Now that is exciting!
Andreas Olofsson is the founder of Adapteva and the creator of the Epiphany architecture and Parallella open source computing project. Follow Andreas on Twitter.
—
References:
[1] RISC-V Instruction Set Architecture: https://riscv.org/download.html#tab\_isaspec
[2] Epiphany Instruction Set Architecture: https://adapteva.com/docs/epiphany_arch_ref.pdf
[3] Implementation of the RISC-V architecture: https://riscv.org/download.html#tab_rocket
[4] A 1024 core 70 GFLOP/W Floating Point Manycore Microprocessor: https://adapteva.com/docs/papers/hpec2011_1024cores.pdf
[5] CoreMark Benchmark Results: https://www.eembc.org/coremark/index.php