admin ·
Epiphany-IV 64-core 28nm Microprocessor (E64G401)
 Introduction
Introduction
The E64G401 is 64-core microprocessor/coprocessor reference design based on the 4th generation of the Epiphany multicore architecture that was designed as a direct replacement of the E16G301. The Epiphany™ architecture defines a multicore, scalable, shared memory, parallel computing fabric and consists of a 2D array of compute nodes connected by a low-latency mesh network-on-chip. The main components of the E64G401 product are shown below. For more detailed information about the Epiphany architecture, please refer to the Epiphany Architecture Reference Manual.
Datasheet:
E64G401 Datasheet (PDF) (Updated June 17, 2013)
Availability:
Chip reference design IP available for licensing in GLOBALFOUNDRIES 28SLP process. Epiphany-IV silicon devices available as part of Parallella boards in Q3/2013.
Features:
- 64 High Performance RISC CPU Cores
- 800 MHz Operating Frequency
- 102 GFLOPS Peak Performance
- 1.6 TB/s Local Memory Bandwidth
- 102 GB/s Network-On-Chip Bisection Bandwidth
- 6.4 GB/s Off-Chip Bandwidth
- 2 MB On-Chip Distributed Shared Memory
- 2 Watt Maximum Chip Power Consumption
- IEEE Floating Point Instruction Set
- Fully-featured ANSI-C/C++ programmable
- GNU/Eclipse based tool chain
- Source synchronous sub-LVDS off chip links for host or direct chip-to-chip interfacing.
- Chip to chip links for integrating up to 64 chips on a single board
- 324-ball 15x15mm flip-chip BGA
RISC Processor:
Each compute node contains an independent superscalar floating-point RISC CPU operating at 800 MHz and 1.6 GFLOPS/sec. The CPU has an efficient general-purpose instruction set that excels at compute intensive applications while being efficiently programmable in C/C++ without any need to write code using assembly or processor specific intrinsics.
Memory System:
The Epiphany memory architecture is based on a flat memory map in which each compute node has a small amount of local memory as a unique addressable slice of the total 32-bit address space. A processor can access its own local memory and other processors memory through regular load/store instructions, with the only difference being the latency and effective throughput of the transactions. The local memory system is comprised of 4 separate banks, allowing for simultaneous memory access by the instruction fetch engine, local load-store instructions, and by load/store transactions initiated by other processors within system.
Network-On-Chip:
The eMesh Network-on-Chip is a 2D mesh network that handles all on-chip ad off-chip communication. The network is based on atomic 32- bit memory transactions and is transparent to the program running. The network consists of three separate and orthogonal mesh structures, each serving different types of transaction traffic: one network for on-chip write traffic, one network for off chip write traffic, and one network for all read traffic.
Off-Chip IO:
The eMesh network and memory architecture is extended off-chip using source synchronous LVDS based serial links that provide up to 1.6GB/sec of effective bandwidth per link. Each E16G401 has 4 links, one in each direction (north, east, west, south), allowing chips to be easily interfaced with FPGAs and/or other E16G401 chips on a board.
System Examples:
The E16G401 product can be used in a number of different system configurations, some of which are shown in this section.
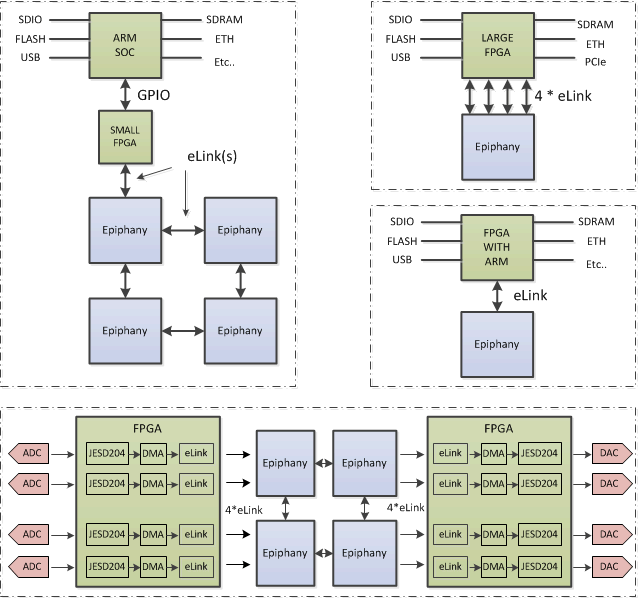
Potential Applications
Consumer:
- Smart-phones and tablet app acceleration
- High end audio
- Computational photography
- Speech Recognition
- Face detection/recognition
Computing Infrastructure:
- Super Computers
- Big Data Analytics
- Software Defined Networking
- Data-center Appliances
- High Frequency Trading
Mil/Aero:
- Radar/Sonar
- Extremely Large Sensor Imaging
- Hyperspectral Imaging
- Communication Jamming
- Military Radios
- Munitions/Guidance
Medical:
- Ultrasound
- CT
Communication:
- Communication test-bed
- Software defined radio
- Adaptive Pre-distortion
Industrial/Instrumentation:
- Machine Vision
- Autonomous Robots/Navigation
- Automotive Safety
- High Speed Data Acquisition/Generation
Other:
- Compression
- Security Cameras
- Video Transcoding